
Hii Everyone!
This is Ravi Kumar, and today I will let you know the understanding of Machine Learning, Architecture, Fine-Tuning, and Training.
Introduction of the ChatGPT
ChatGPT is a state-of-the-art language model developed by OpenAI. It is designed to understand and generate human-like text. This tutorial will explore how ChatGPT uses machine learning and neural networks, the architecture behind GPT-4, fine-tuning for specific tasks, and the training process involved in developing ChatGPT.
How ChatGPT Uses Machine Learning and Neural Networks
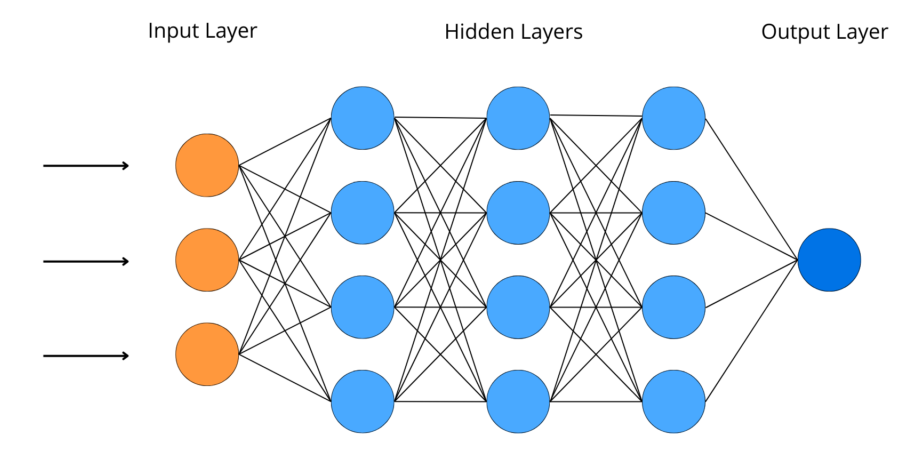
Machine Learning
Machine Learning (ML) is a branch of artificial intelligence (AI) that focuses on training algorithms to learn from data and make predictions or decisions.
- Supervised Learning: This approach involves training the model on a dataset where each input is paired with a correct output. ChatGPT uses supervised learning during its fine-tuning phase, learning from examples of human interactions.
- Unsupervised Learning: In this approach, the model attempts to identify patterns and structures in the data without explicit labels. ChatGPT leverages unsupervised learning during its pre-training phase, absorbing language patterns from a vast corpus of text.
Neural Networks
Neural Networks are computational models inspired by the human brain, consisting of layers of interconnected nodes (neurons). These networks learn to recognize patterns through processes such as backpropagation, where weights are adjusted based on error rates.
- Transformer Architecture: ChatGPT is built on the transformer architecture, which uses self-attention mechanisms to process input data. This enables the model to focus on different parts of the input sequence and understand context more effectively than previous models like RNNs and LSTMs.
- Self-Attention Mechanism: This mechanism allows the model to weigh the importance of different words in a sentence relative to each other, capturing context and dependencies.
The Architecture Behind GPT-4
GPT-4 is an advanced generative language model in the Generative Pre-trained Transformer (GPT) series, building on the strengths of its predecessors.
Key Components
- Layers: GPT-4 consists of multiple layers, each containing attention mechanisms and feedforward neural networks. More layers generally mean a greater capacity to learn complex patterns.
- Attention Heads: Each layer in GPT-4 has multiple attention heads, which allow the model to focus on different parts of the input simultaneously, capturing various aspects of the context.
- Positional Encoding: Transformers lack a built-in sense of order, so positional encoding is used to introduce sequence information to the input data, helping the model understand word order.
Training and Scalability
- Large-scale Datasets: GPT-4 is trained on extensive datasets covering diverse domains and languages, enabling it to generalize across various topics and contexts.
- Parameter Count: GPT-4 has a significantly larger number of parameters compared to its predecessors, allowing it to capture more nuances and generate more accurate responses.
- Parallel Processing: Training such a large model requires distributed computing across multiple GPUs or TPUs to handle the computational load.
Fine-Tuning ChatGPT for Specific Tasks
Fine-tuning involves further training a pre-trained model on a specific dataset tailored to a particular task, enabling it to adapt and specialize in certain areas.
Steps in Fine-Tuning
- Data Collection: Gather a dataset specific to the task. For instance, to fine-tune ChatGPT for customer support, collect a large set of customer service interactions.
- Preprocessing: Clean and preprocess the dataset to ensure it is suitable for training. This might involve tokenization, normalization, and filtering out irrelevant data.
- Training: Initialize the pre-trained GPT-4 model and train it on the specialized dataset using supervised learning. The model adjusts its weights to minimize prediction errors on the new data.
- Evaluation: Continuously evaluate the model’s performance on a validation set to ensure it is learning effectively and not overfitting. Adjust training parameters based on performance metrics.
- Deployment: After fine-tuning, the specialized model can be deployed for a specific task, such as providing accurate customer support or generating medical advice.
Understanding the Training Process of ChatGPT
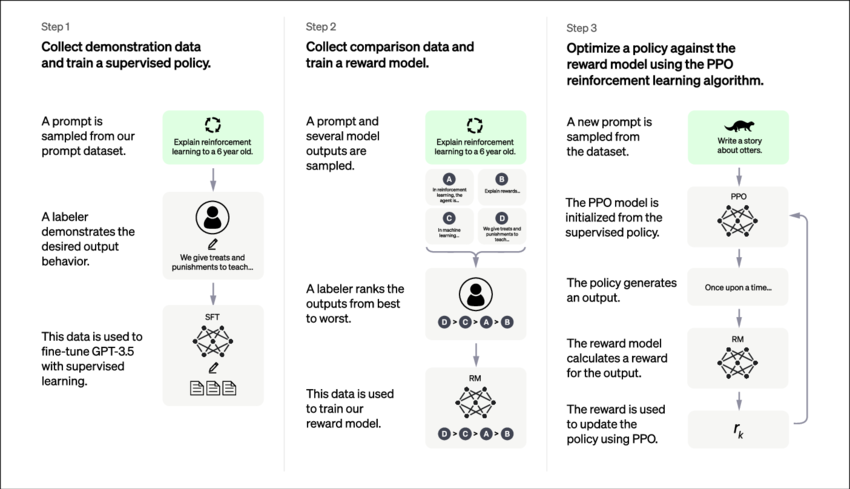
The training process involves several stages, from initial data processing to the final model. Here’s an overview of each step:
Pre-Training
- Corpus Collection: Gather a vast and diverse dataset from books, websites, and other text sources. This dataset should cover a wide range of topics and language uses.
- Tokenization: Convert the text into tokens (words or subwords). Tokenization breaks down the text into smaller units that the model can process.
- Model Training: Train the model using unsupervised learning. During this phase, the model learns to predict the next token in a sequence based on the context provided by previous tokens. The model adjusts its weights to minimize prediction errors.
Fine-Tuning
- Domain-Specific Dataset: Collect a dataset tailored to the specific task for which the model will be fine-tuned.
- Supervised Learning: Train the model on this dataset, using labeled examples to adjust the model’s parameters for better performance on the task.
Evaluation and Iteration
- Validation: Test the model on a separate validation dataset to evaluate its performance. Use metrics such as accuracy, precision, recall, and F1 score to measure effectiveness.
- Iteration: Refine the model by iteratively adjusting training parameters and retraining to improve performance.
Deployment
- Integration: Integrate the fine-tuned model into applications where it can perform specialized tasks, such as chatbots, virtual assistants, or automated content generation tools.
Conclusion
ChatGPT, particularly GPT-4, represents a significant advancement in natural language processing and AI. Its foundation in machine learning and neural networks, combined with its sophisticated transformer architecture, enables it to generate human-like text. The model’s capabilities are further enhanced through fine-tuning for specific tasks and a comprehensive training process. Understanding these technical insights provides a deeper appreciation of how ChatGPT functions and its potential applications in various domains.
Thanks!